生成器(generator)
一.什么是生成器
通过列表生成式,我们可以直接创建一个列表。但是,受到内存限制,列表容量肯定是有限的。而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器:generator。
二.创建生成器的方法
1).第一种方法很简单,只要把一个列表生成式的 [ ] 改成 ( )
l=[x*2 for x in range(10)]#l为列表g=(x*2 for x in range(10))#g为生成器print(l)print(g)

创建 l和 g的区别仅在于最外层的 [ ] 和 ( ) , L 是一个列表,而 G 是一个生成器。我们可以直接打印出L的每一个元素,但我们怎么打印出G的每一个元素呢?如果要一个一个打印出来,可以通过 next() 函数获得生成器的下一个返回值:
g=(x*2 for x in range(10))print(next(g))for i in g: print(i)
生成器保存的是算法,每次调用 next(G) ,就计算出 G 的下一个元素的值,直到计算到最后一个元素,没有更多的元素时,抛出 StopIteration 的异常。当然,这种不断调用 next() 实在是太变态了,正确的方法是使用 for 循环,因为生成器也是可迭代对象。所以,我们创建了一个生成器后,基本上永远不会调用 next() ,而是通过 for 循环来迭代它,并且不需要关心 StopIteration 异常。
2).generator非常强大。如果推算的算法比较复杂,用类似列表生成式的 for 循环无法实现的时候,还可以用函数来实现;
例如斐波拉契函数生成器
def fib(times): n=0 a,b=0,1 while n
在上面fib 的例子,我们在循环过程中不断调用 yield ,就会不断中断。当然要给循环设置一个条件来退出循环,不然就会产生一个无限数列出来。同样的,把函数改成generator后,我们基本上从来不会用 next() 来获取下一个返回值,而是直接使用 for 循环来迭代:
def fib(times): n=0 a,b=0,1 while n
但是用for循环调用generator时,发现拿不到generator的return语句的返回值。如果想要拿到返回值,必须捕获StopIteration错误,返回值包含在StopIteration的value中:
def fib(times): n=0 a,b=0,1 while n
三.send
send方法和next方法唯一的区别是在执行send方法会首先把上一次挂起的yield语句的返回值通过参数设定,从而实现与生成器方法的交互。但是需要注意,在一个生成器对象没有执行next方法之前,由于没有yield语句被挂起,所以执行send方法会报错。
def gen(): i=0 while i<5: temp=yield i print(temp) i+=1f=gen()print(next(f))print(next(f))print(f.__next__())#等价于next(f),等价于f.send(None)print(f.send("hello")) 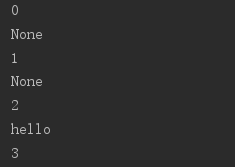
四.小结
生成器是这样一个函数,它记住上一次返回时在函数体中的位置。对生成器函数的第二次(或第 n 次)调用跳转至该函数中间,而上次调用的所有局部变量都保持不变。
生成器不仅“记住”了它数据状态;生成器还“记住”了它在流控制构造(在命令式编程中,这种构造不只是数据值)中的位置。
生成器的特点:
- 节约内存
- 迭代到下一次的调用时,所使用的参数都是第一次所保留下的,即是说,在整个所有函数调用的参数都是第一次所调用时保留的,而不是新创建的